











Ollama Illustrator
中文简体 | 多国语言
Windows | macOS | Linux
Ollama 是一款 2023 年底推出的开源跨平台大语言模型工具,核心作用是简化大型语言模型的本地部署与管理,让用户无需依赖云服务和复杂基础设施就能便捷使用大模型Ollama。它适配 Windows、macOS、Linux 等系统,凭借 4 - bit 量化技术降低显存需求,普通消费级电脑甚至 8GB 内存的设备也能运行轻量模型Ollama。该软件兼容 Llama 3、DeepSeek、Qwen 等 30 多种主流开源模型,还支持导入 GGUF 等格式的自定义模型,用户通过一行命令就能完成模型的下载、启动与运行,同时提供 REST API 及 Python/JavaScript SDK,可无缝对接 LangChain 等框架Ollama。此外,它允许通过编写 Modelfile 调整模型推理参数来创建个性化模型,数据交互全程在本地完成,能保障隐私安全,广泛适配开发者测试、企业内部文档问答、科研教学等多种场景。

点击「Download」下载安装包(约1.26+GB)
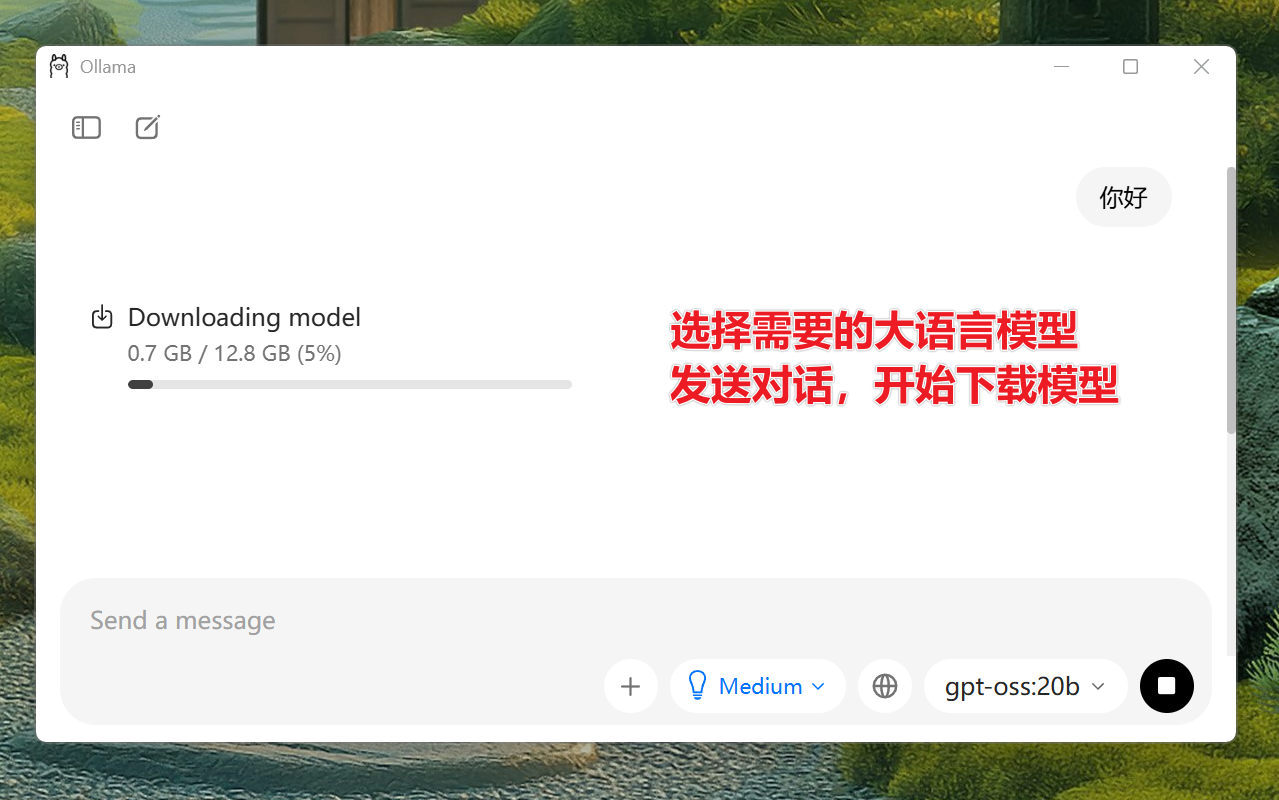
Ollama大语言模型下载推荐
一、优先选择(完美适配 16G 显存)
-
gemma3:12b
- 显存需求:4bit 量化版约 6-7GB,16G 显存留足冗余;
- 优势:Google 推出的模型,中文理解、代码生成能力较强,推理速度快(15-25 tokens/s);
- 适配场景:Clawdbot 的日常交互、自动化脚本开发。
-
deepseek-r1:8b
- 显存需求:4bit 量化版约 4-5GB;
- 优势:代码能力突出,适配 ComfyUI/SketchUp 的指令控制场景,响应速度快;
- 适配场景:工具调用、代码生成类任务。
二、谨慎选择(接近 16G 显存上限)
- qwen3:8b
- 显存需求:4bit 量化版约 4-5GB,8bit 版约 8-9GB;
- 优势:中文能力强,与 Qwen2.5-14B 同源,切换无适应成本;
- 注意:若选 8bit 版,需预留足够显存,避免同时运行其他程序。
三、不推荐选择(显存不足 / 性能瓶颈)
gpt-oss:20b/qwen3:30b等 20B + 参数模型:4bit 量化版显存占用超 16GB,无法稳定运行;*-cloud后缀模型:依赖云端服务,存在断连 / 额度限制风险,不如本地模型稳定。
四、Ollama没有列出的其他模型推荐
通义千问2.5-14B-Instruct-GGUF(适合16G显存使用,单文件适合Ollama,)
- 下载模型:
在这个网页查找:qwen2.5-14b-instruct-q4_k_m.gguf
- 文件大小:8.99GB(merged split 合并后的单文件,无拆分);
- 量化级别:Q4_K_M(4bit 最优量化版本);
- 核心优势:
- 显存占用≈9GB,16G 显存剩余 7GB 冗余,运行稳定不崩溃;
- 推理速度快(15-20 tokens/s),适配 Clawdbot 实时交互;
- 是单文件 GGUF 格式,可直接导入 Ollama,无需处理拆分文件;
- Q4_K_M 是 4bit 量化中效果最优的版本,兼顾性能和精度。
- 下载后安装:
步骤 :下载的模型存到一个位置
如:C:\AiModels\Ollama_Models\qwen2.5-14b-instruct-q4_k_m.gguf
步骤 2:重新生成正确的 Modelfile(全小写参数)
在 PowerShell 中执行以下命令(复制粘贴即可),注意
parameter是全小写:# 写入模型路径(FROM首字母大写是正确的,仅parameter需小写)
echo "FROM C:\AiModels\Ollama_Models\qwen2.5-14b-instruct-q4_k_m.gguf" > modelfile
# 写入硬件/参数配置(parameter全小写)
echo "parameter num_gpu 1" >> modelfile
echo "parameter num_ctx 8192" >> modelfile
echo "parameter temperature 0.7" >> modelfile步骤 3:重新导入模型到 Ollama
执行导入命令
ollama create qwen2.5:14b-instruct -f modelfile步骤 4:验证导入结果
导入完成后,执行以下命令查看模型列表:
ollama list如果列表中出现
qwen2.5:14b-instruct,说明导入成功;若想测试模型是否能运行,执行:ollama run qwen2.5:14b-instruct输入
你好,能收到回复即代表模型正常工作。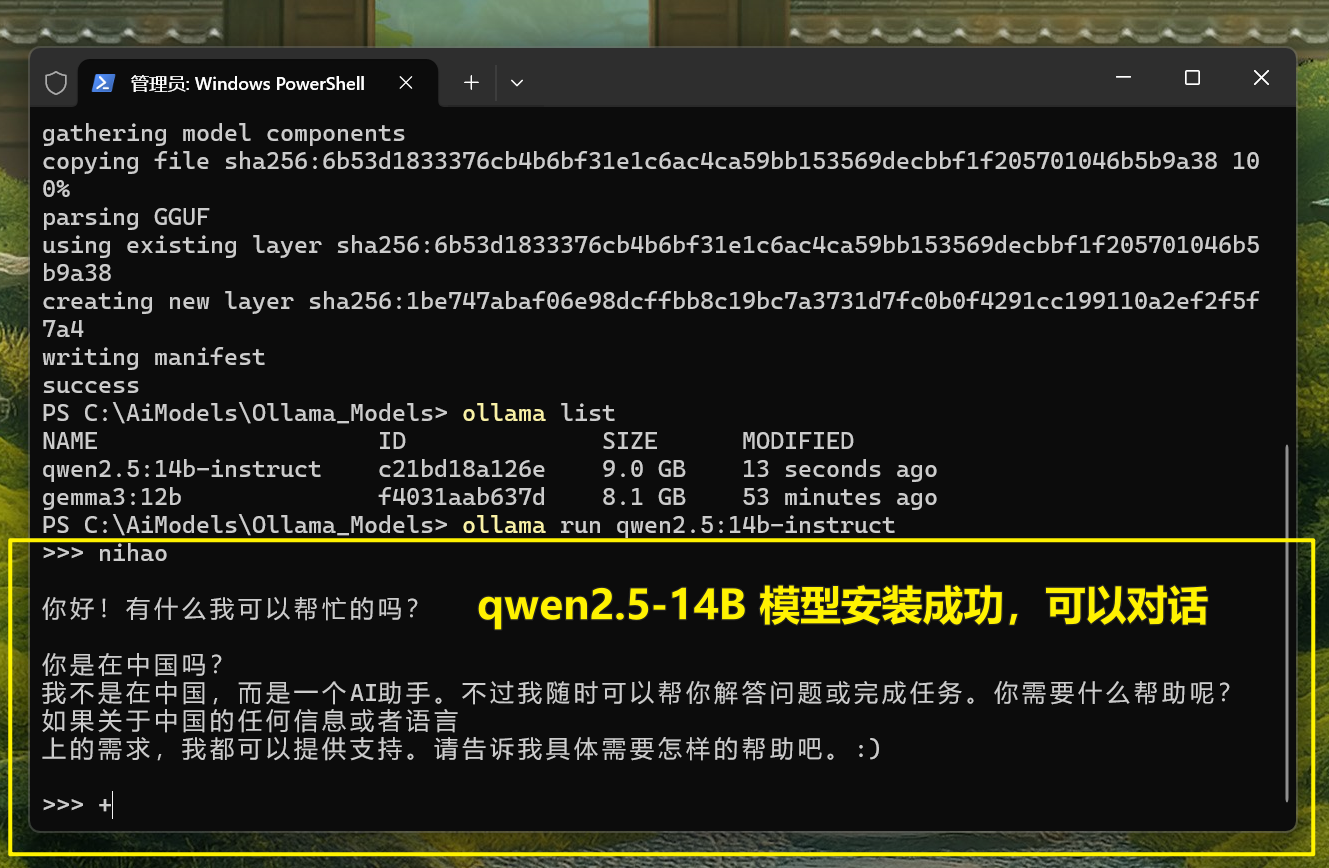
相关导航





暂无评论...